Моделирование и анализ данных
2022. Том 12. № 3. С. 49–57
doi:10.17759/mda.2022120304
ISSN: 2219-3758 / 2311-9454 (online)
О методе распознавания голосовых команд с применением особого преобразования спектральных плотностей
Аннотация
Общая информация
Ключевые слова: автоматическое распознавание речи, спектральный анализ, сверточные нейронные сети
Рубрика издания: Комплексы программ
Тип материала: научная статья
DOI: https://doi.org/10.17759/mda.2022120304
Для цитаты: Левонович Н.И. О методе распознавания голосовых команд с применением особого преобразования спектральных плотностей // Моделирование и анализ данных. 2022. Том 12. № 3. С. 49–57. DOI: 10.17759/mda.2022120304
Полный текст
Ведение
Одной из наиболее актуальных проблем в области человеко-машинных интерфейсов в настоящий момент является создание голосовых интерфейсов. Это направление включает в себя исследования в области распознавания речи, синтеза речи, обработки естественного языка и интеллектуальной интерпретации речи.
В настоящее время существует несколько подходов к распознаванию речи для разных модулей системы распознавания речи. Эти модули – акустическая модель, языковая модель и декодер. Современные средства распознавания речи комбинируют различные методы: алгоритм динамической трансформации временной шкалы, методы дискриминантного анализа, основанные на байесовской дискриминации, скрытые марковские модели, нейронные сети.
Акустическая модель — это функция, принимающая на вход признаки на небольшом участке акустического сигнала (фрейме) и выдающая распределение вероятностей различных фонем на этом фрейме. Самой популярной моделью акустического моделирования являются скрытые марковские модели, однако в свежих работах [Sak, Haşim, et] встречаются модели, использующие рекуррентные нейронные сети, в частности LSTM-сети (сети долгой краткосрочной памяти), и нейросетевую темпоральную классификацию (СTC).
Языковые модели позволяют учитывать контекст и выяснять, какие последовательности слов и фонем являются наиболее вероятными с точки зрения текущего контекста. Современные средства языкового моделирования так же используют рекуррентные нейронные сети.
Декодер на базе вероятностей, предоставленных акустической и языковой моделью, выбирает конкретную речевую единицу.
Новый подход к распознаванию речи
Схема команд, представленных в данном наборе (граф переходов между словами), представлена на рисунке 1.

Рисунок 1 – Граф построения голосовой команды
С целью создания модели для распознавания был собран набор данных – записей различных голосовых команд, сделанных разными дикторами. Записи набора данных были сделаны шестьюдесятью дикторами. Всего исходный набор данных содержит 1129 голосовых команд. Максимальная продолжительность звукового сигнала команды 4 секунды.
На данном наборе данных можно поставить 2 задачи многоклассовой классификации: классификация произнесенных команд – 60-ти классовая классификация, поиск и классификация произнесенных слов – 14-ти классовая классификация.
В рамках данной статьи будет рассмотрено решение задачи 14-ти классовой классификации произнесенных слов, так как на данном наборе данных она представляется более разрешимой. Базовым методом для решения данной задачи был выбран метод анализа спектральных плотностей [Л. С. Куравский, 2012] с помощью свёрточных нейронных сетей [Dumoulin, Vincent, and].
Разделение сигналов на слова производилось с помощью оконного подсчета энергии сигнала и выборке областей, в которых энергия больше энергии шума.
С целью улучшения разделения слов и дальнейшей дискриминации был предложен метод предобработки спектрограмм. Сущность метода – логарифмирование с предварительным прибавлением перцентиля спектрограммы и минимального значения сигнала (шага амплитуды) . Одна из реализаций метода выражается формулой 1 (используется 85-тый перцентиль). К полученной модифицированной логарифмированной спектрограмме было применено масштабирование к диапазону [0;255] и взятие целой части (формула 2).
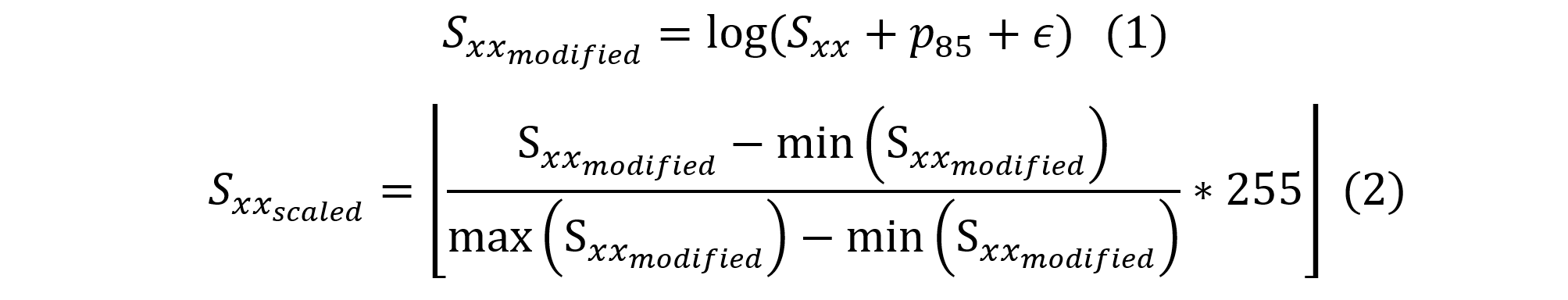
Модифицированные спектрограммы были разбиты на слова раннее описанным методом. В качестве энергии в этом случае выступала сумма амплитуд. Максимальная длинна слова в выборке при разбиении 105 отсчетов спектрограммы (что примерно соответствует 1,47 секундам). Все полученные спектрограммы слов были преобразованы к размеру 382x105, путем добавления нулевых столбцов в матрицу справа от матрицы спектрограммы.
На подготовленных таким образом данных была обучена свёрточная модель архитектуры, изображенной на рисунках 2-3.
Данная модель была обучена оптимизатором Adam, с шагом обучения 0.002. Перед началом обучения обе выборки были разбиты на обучающую и контрольную подвыборки, в отношении 75% и 25%. В подвыборках сохранялось исходное соотношение классов. По результатам обучения данной модели на тестовой выборке было получено 97.09% (Рисунок 4).

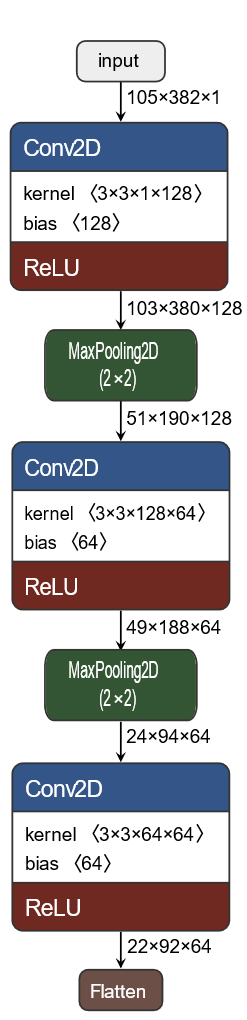
Рисунок 2 – Архитектура свёрточной модели (свёрточная часть)
При использовании данной модели для распознавания команд 873 из 1129 команд были распознаны верно, что соответствует ~77%.
С целью улучшения качества распознавания была предпринята попытка обучить отдельные полносвязные модели для каждой позиции. Все отдельные модели базировались на общих свёрточных слоях, изображенных на рисунке 2. Архитектура отдельных моделей изображена на рисунке 5 (модели идут слева на право, также как в графе переходов между словами). Модели позволяют различать соответствующие позиции слова между собой и отличать их от других слов.
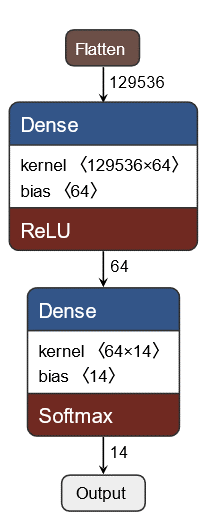
Рисунок 3 – Архитектура свёрточной модели (полносвязная часть)

Рисунок 4 – Доля верных ответов на контрольной выборке

Данные модели были обучены оптимизатором Adam, с шагом обучения 0.002. Перед началом обучения обе выборки были разбиты на обучающую и контрольную подвыборки, в отношении 75% и 25%.
Максимальная достигаемая с применением данного метода доля верных ответов на тестовой выборке - 98% слов. Однако при распознавании команд данный метод показал себя хуже. 841 из 1129 команд были распознаны верно, что соответствует ~74%.
Еще одним подходом, который был применен при решении данной задачи – наивный байесовский классификатор на выходах нейросети, изображенной на рисунках 2 и 3. При обычной интерпретации выходов нейросети берется аргумент максимизации выходного слоя (формула 3).
При использовании наивного байесовского классификатора [Ch, Read, and] аргумент максимизации берется от произведения входа нейросети на априорную вероятность класса , которая задается графом переходов между словами (формула 4).
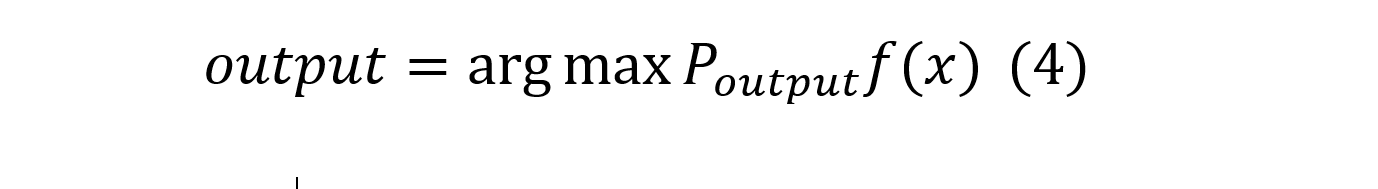
Конкретные априорные вероятности слов для каждой позиции приведены в таблице 1.
Таблица 1 Априорные вероятности слов на позиции.
|
|
1 |
2 |
3 |
4 |
|
1 |
2 |
3 |
4 |
|
bed |
0 |
0 |
0 |
left |
0 |
0 |
0 |
||
|
bird |
0 |
0 |
0 |
one |
0 |
0 |
0 |
||
|
cat |
0 |
0 |
0 |
right |
0 |
0 |
0 |
||
|
dog |
0 |
0 |
0 |
sheila |
1 |
0 |
0 |
0 |
|
|
five |
0 |
0 |
0 |
three |
0 |
0 |
0 |
||
|
four |
0 |
0 |
0 |
tree |
0 |
0 |
0 |
||
|
house |
0 |
0 |
0 |
two |
0 |
0 |
0 |
При использовании данного метода верно были классифицированы 977 из 1129 команд, точность классификации составила 87%.
Для демонстрации, обученной по предложенному методу, нейросети было разработано настольное программное обеспечение на языке Python с использованием графического интерфейса Kivy [Virbel, Mathieu, Thomas, 2011]. Данное приложение использует модель с наивным байесовским классификатором. Разработанное программное обеспечение представляет собой, однооконное приложение, которое позволяет выбрать файл и распознать его. Пример работы приложения изображен на рисунке 6.
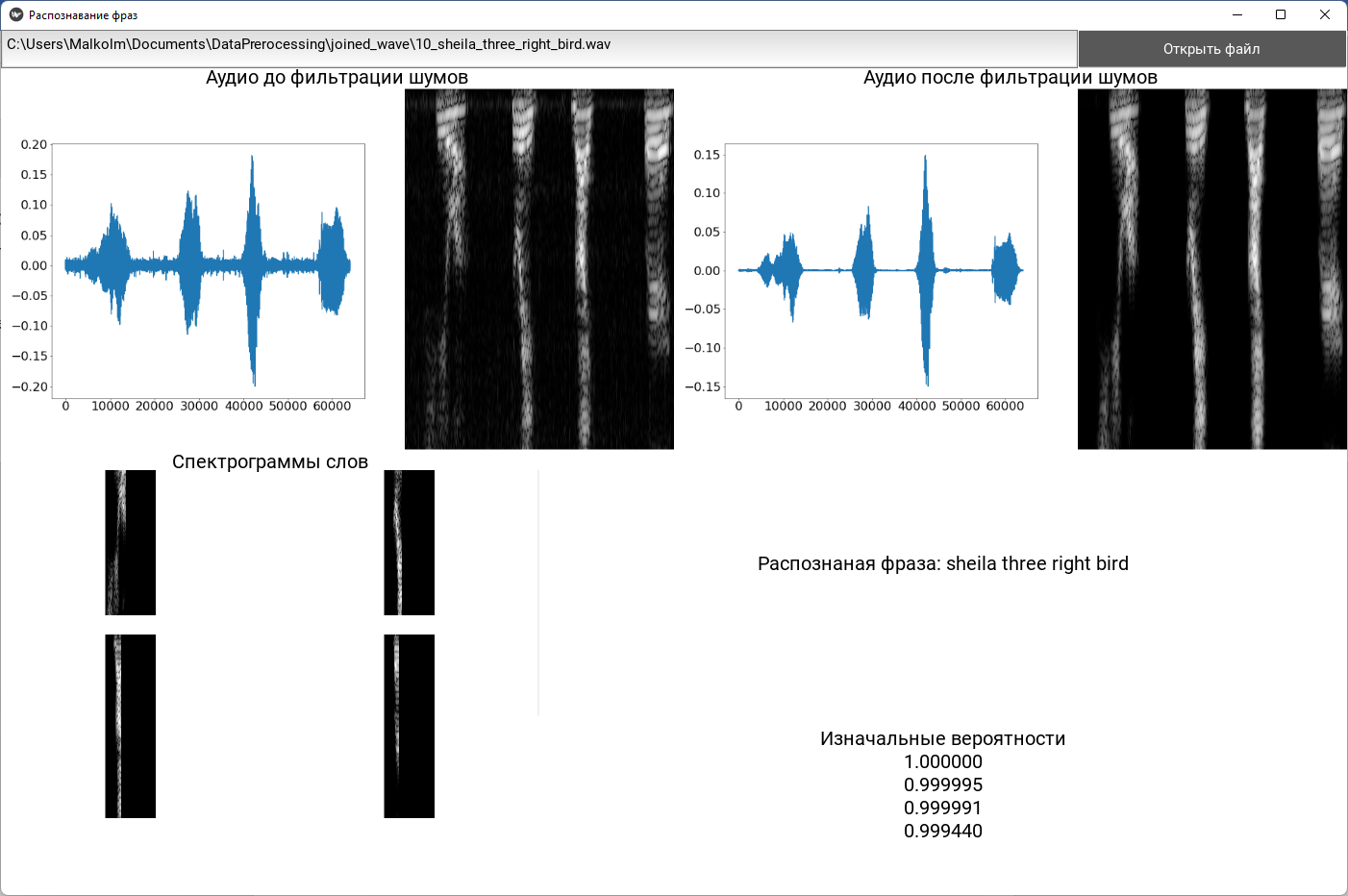
Рисунок 6 – Пример работы приложения
Приложение считывает аудиофайл с диска, строит график и спектрограмму исходного сигнала (левая верхняя четверть), фильтрует шумы и строит график и спектрограмму отфильтрованного сигнала (правая верхняя четверть). После чего сигнал разбивается на слова, спектрограммы которых изображаются в левой нижней четверти. Ответы модели в виде распознанной фразы и исходных (до применения байесовского аргумента максимизации) максимальных вероятностей выводятся в правой нижней четверти.
Заключение
В данной работе предложен новый метод обработки спектрограмм, который существенно повышает сходимость обучения свёрточных нейронных сетей для решения задачи классификации произнесенных слов. С помощью него разработан метод распознавания голосовых команд, который на представленной выборке дает точность классификации 87%. Данный результат является достаточно высоким, однако не достаточным для практического применения, его необходимо усовершенствовать. Одним из путей усовершенствования может быть распознавание фразы целиком, однако такая модель будет более тяжеловесной и, возможно, потребует более объемной выборки.
Литература
- Sak, Haşim, et al. "Fast and accurate recurrent neural network acoustic models for speech recognition." arXiv preprint arXiv:1507.06947 (2015).
- Л. С. Куравский, С. Н. Баранов Компьютерное моделирование и анализ данных. Конспекты лекций и упражнения: Учеб. пособие. – М.: РУСАВИА, 2012. – 218 с.:
- Dumoulin, Vincent, and Francesco Visin. "A guide to convolution arithmetic for deep learning." arXiv preprint arXiv:1603.07285 (2016).
- Ch, Read, and ML MAP. "Bayesian learning." book: Machine Learning. McGraw-Hill Science/Engineering/Math (1997): 154-200.
- Virbel, Mathieu, Thomas Hansen, and Oleksandr Lobunets. "Kivy–a framework for rapid creation of innovative user interfaces." Workshop-Proceedings der Tagung Mensch & Computer 2011. überMEDIEN| ÜBERmorgen. Universitätsverlag Chemnitz, 2011.
Информация об авторах
Метрики
Просмотров web
За все время: 338
В прошлом месяце: 17
В текущем месяце: 6
Скачиваний PDF
За все время: 121
В прошлом месяце: 3
В текущем месяце: 1
Всего
За все время: 459
В прошлом месяце: 20
В текущем месяце: 7